Commander’s Corner: A Message from COL Jeremy Pamplin & Team TATRC
Tuesday, April 30, 2024 | Download PDF

We are off to the races! Since our last update, TATRC has been a whirlwind of activity. Never have I witnessed the organization humming along like such a finely-tuned engine – we have transformed. For most of its history, TATRC’s primary function was execution management: receiving proposals, awarding funds to external entities and ensuring the completion of that research. Now we are an organizational team focused on a mission and we are all working together to accomplish it through programmatic research (Figure 1). It has been remarkable to watch this team do such incredible things! We are truly blessed to have phenomenal individuals working at TATRC – from our science teams to our science support and command staff, our contractors, civilians, and military – everyone is invested and focused on delivering new capabilities to help modernize military medicine. I’m immensely proud of the work TEAM TATRC has accomplished over the past six months and excited to see what the future holds!
More on Automating Casualty Care:
The last two Commander’s Corners have highlighted the importance of automating casualty care to increase capability and capacity on the future battlefield and how this could be done following examples from industry, specifically the automotive industry’s climb to summit Mount Autonomy. We’ve introduced many concepts around passive data collection and why we are working to automate tactical combat casualty care (TC3) documentation as our first material product solution, a project we affectionately call “AutoDoc.”
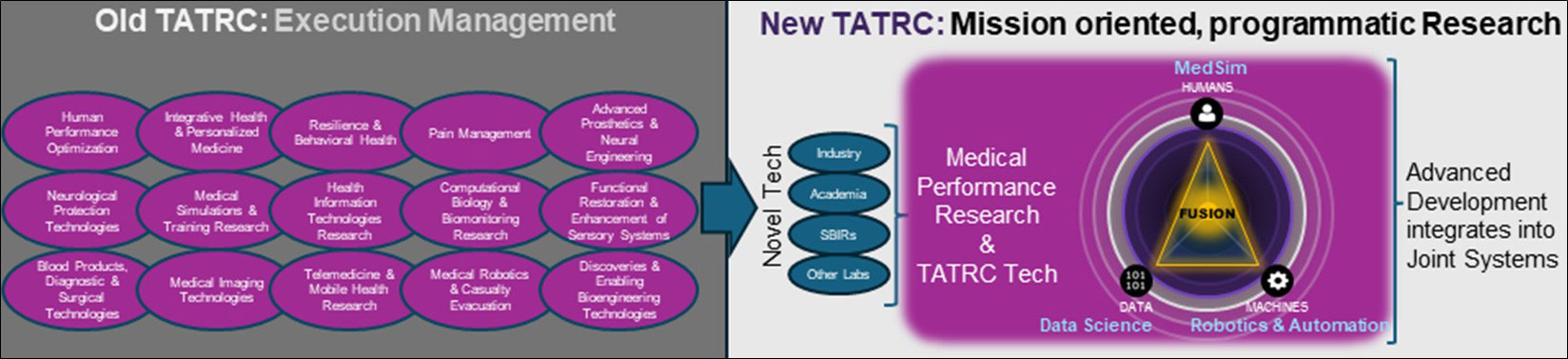 Figure 1. The old TATRC was primarily an execution management agency with numerous portfolios like the Congressionally Directed Medical Research Programs. The “new” TATRC, has been evolving since about 2012 into a mission oriented, programmatic research lab, now focused on automating casualty care and understanding the Military Healthcare Systems Medical Performance of Casualty Care.
Figure 1. The old TATRC was primarily an execution management agency with numerous portfolios like the Congressionally Directed Medical Research Programs. The “new” TATRC, has been evolving since about 2012 into a mission oriented, programmatic research lab, now focused on automating casualty care and understanding the Military Healthcare Systems Medical Performance of Casualty Care.
This quarter I’d like to share more details about how TATRC intends to move from a paradigm in which casualty care is exclusively in the human domain to one of increasing human-technology teaming and automation (Figure 2) to meet the anticipated challenges of all-domain operations against near-peer adversaries: massive numbers of casualties and the need to care for them for prolonged periods. We will also cover some of the key concerns regarding our approach. Hopefully, by the end, there will be more clarity about how TATRC intends to grow the automation portfolio in an ambitious but expeditious and thoughtful manner.
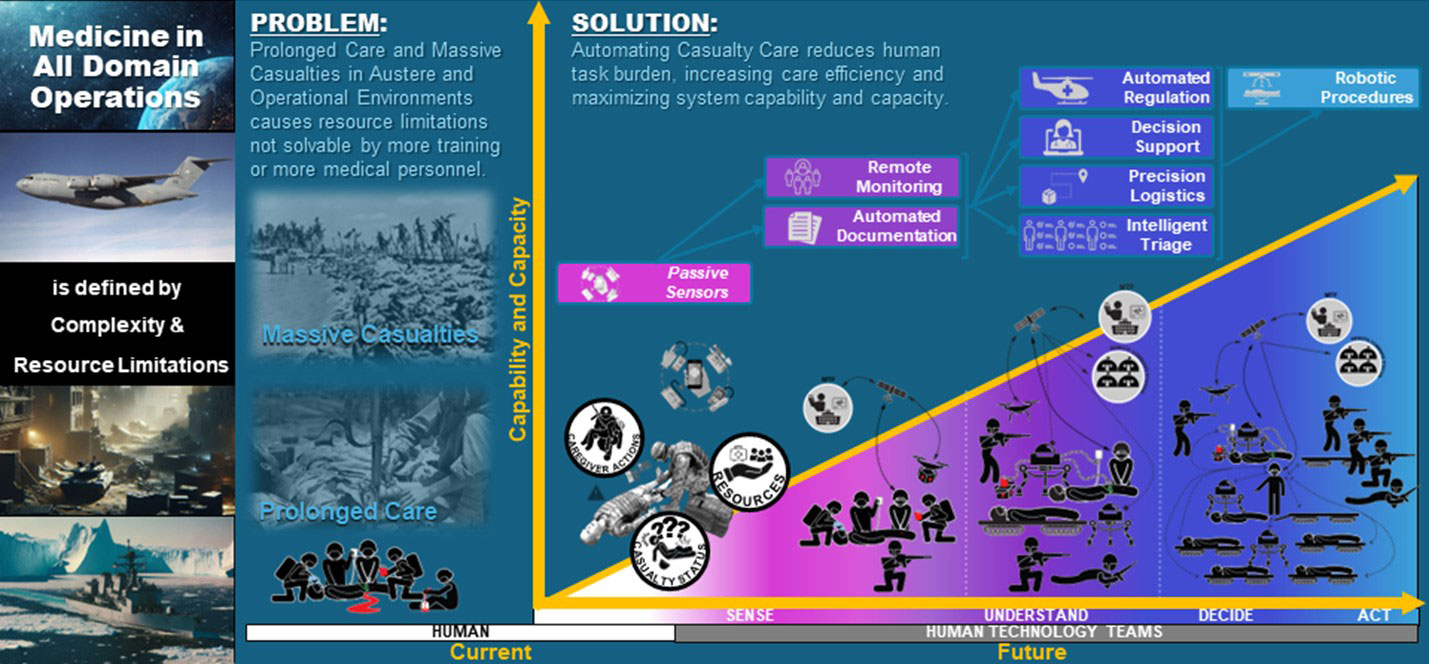 Figure 2. Large Scale Combat Operations against peer adversaries in all domain operations challenges the military health systems to deliver sufficient medical capability at scale. To address this challenge, we must transition from casualty care delivered entirely by humans to casualty care delivered increasingly by human-technology teams.
Figure 2. Large Scale Combat Operations against peer adversaries in all domain operations challenges the military health systems to deliver sufficient medical capability at scale. To address this challenge, we must transition from casualty care delivered entirely by humans to casualty care delivered increasingly by human-technology teams.
First, training artificial intelligence (AI) models to automate complex tasks like driving or documenting casualty care is dependent upon having data that is sufficiently representative of the task. This data must be accurate, reliably available, collected at a frequency that enables machine performance to be comparable to a human’s, and be inclusive of the contextual variations of the task we wish to automate. For example, the computer may not interpret data it “sees” from driving on a sunny day in the same way it “sees” driving on a rainy day. The same holds true for interpreting medical tasks under different conditions.
Data that we build our ecosystem around must be reliably collected and useful in contexts: the light and the dark, the loud and the silent, the clean and the muddy (or bloody), the hot and the dry and the cold and the wet. We assume that one data source (like video) will be insufficient and that we can identify a set of SWaPC31 compliant, caregiver worn sensors that will be unobtrusive to TC3 performance. We start from the premise that is it better to build a system around data that is reliably collectable and accurate across all care environments. We must rigorously test these assumptions, recalibrate our approach, and invest in new sensors or sensor configurations. We must do this until we have a dataset that is sufficiently reliable, accurate, and robust enough to create our system around.
In the context of AutoDoc, we need data from real-combat casualty care that represents the ground truth about what casualties look like, what caregivers do, and what resources they use to care for casualties during TC3 in all combat environments. Historical data is not available, as it was not recorded, and there is limited combat casualty care conducted at present. So, where can we get this data from?
TATRC proposes the Data Nexus (Figure 3) as a model for collecting data about TC3 and, in the future, from all echelons of care. In this model, a core data set from unobtrusive, reliable, SWaPC3 compliant ground truth sensors are collected from the laboratory environment, casualty care training (specifically student or team validation testing), and real-world patient care (primarily civilian or garrison based until a fieldable sensor suite is identified and made available during real combat casualty care). We acknowledge that datasets collected from each of these environments – lab, training, and civilian or garrison care – will have inherent biases that could affect future AI models. For example, data collected from the lab may not represent C3 contexts of dirt, snow, or complexity; data collected from training may not represent the experience of treating a real human, or the time pressures from mission or enemy threat; and data collected from civilian or garrison based patient care may not represent the same sequence of C3 expected in military context and that it is provided by caregivers without the same knowledge, skills, abilities, experience, sets, kits, and outfits (KSAs and SKOs) as military pre-hospital caregivers. One example of a key difference between the care delivered during real C3 on a battlefield and all other domains available to collect data from, is the probability that a caregiver is delivering C3 to a friend or colleague – a rarity in training, civilian, or garrison healthcare, but a 99% probability for a military pre-hospital provider during combat. It is important to note that these differences in context will produce data that has differences from real C3 in combat. Models produced from this data will therefore be biased. We must be intentional about identifying solutions that will minimize these biases, or be able to correct for them, when we transition the models to real C3 applications.
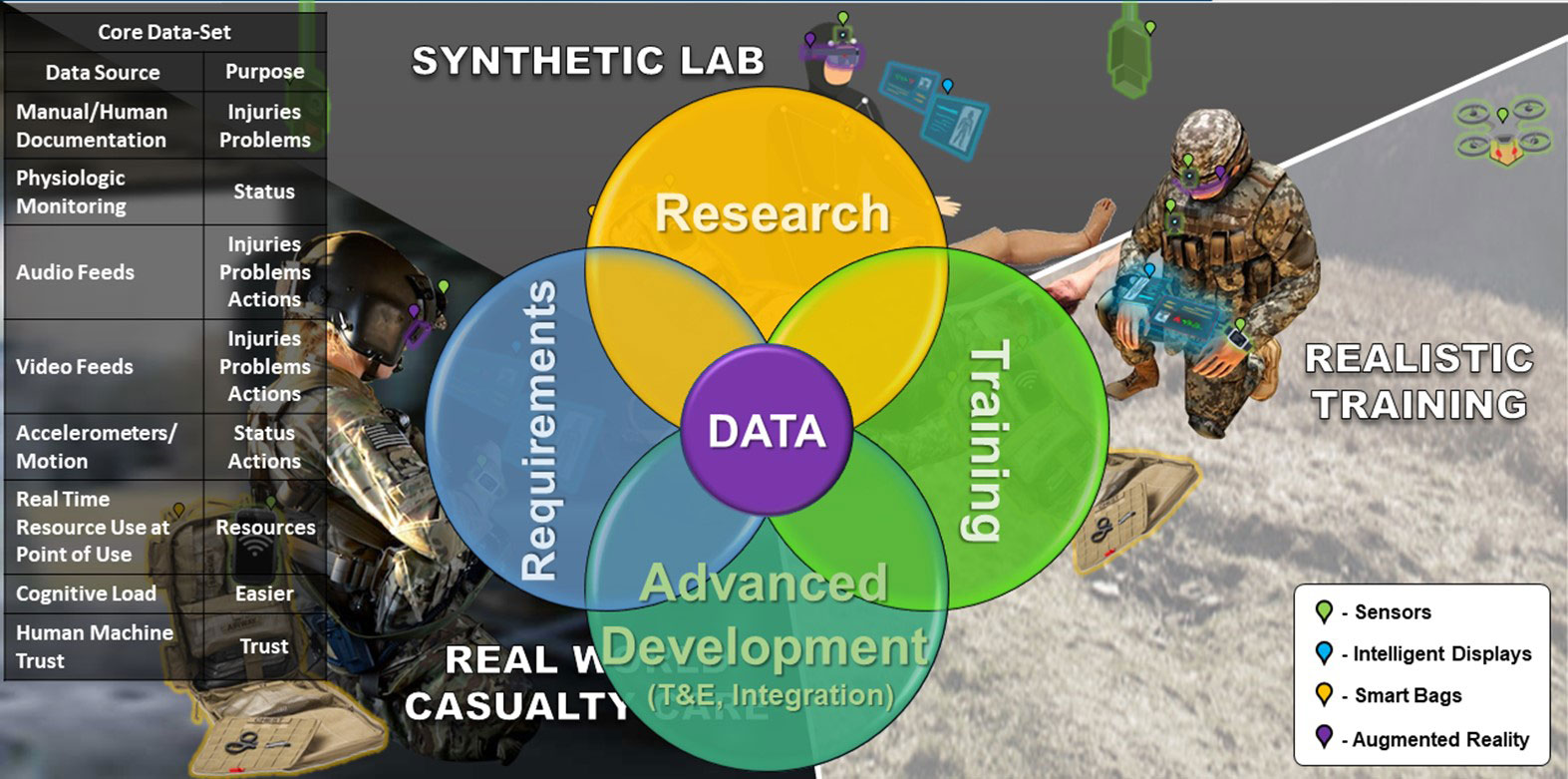 Figure 3. The Data Nexus. A core data set that represents casualty care can be collected using unobtrusive ground truth (passive, real-time data not interpreted by humans) sensors from research, testing/training, and real-world civilian and military environments. Using this data, we can learn to improve care delivery, training, and requirements generation. We can also model the data to produce material products like autonomous documentation, intelligent decision support, and advanced triage solutions.
Figure 3. The Data Nexus. A core data set that represents casualty care can be collected using unobtrusive ground truth (passive, real-time data not interpreted by humans) sensors from research, testing/training, and real-world civilian and military environments. Using this data, we can learn to improve care delivery, training, and requirements generation. We can also model the data to produce material products like autonomous documentation, intelligent decision support, and advanced triage solutions.
How much data do we really need and how much can we actually collect? These are unknowns at present. Preliminary experience published by the Trauma THOMPSON1 group suggests that even with a relatively small dataset, AI can learn to recognize TC3 tasks. In collaboration with these investigators, and others working in this domain, developing a large dataset with thousands of TC3 tasks and scenarios (tasks for machine recognition, scenarios for task sequencing) is necessary, but may be insufficient. In addition to data collected from the physical world, we must also augment our datasets – introducing variations and complexity to it like shadows, rain, obstructions, different shapes and sizes of casualties and caregivers, signal loss, etc. We anticipate harnessing gaming applications and generative AI in the future to help produce additional data for training algorithms, but these applications and the generative AI need baseline data from the care context of interest to compare against, or else we risk introducing significant bias to algorithms from the larger volume of synthetic data we create. In other words, we need the ground truth data from the real-world to avoid biasing models produced from synthetic data.
Collecting data from the Data Nexus is no small undertaking – stakeholders in each of these domains have different perspectives, priorities, and motivations. Policies for data collection, storage, and usage vary within each domain and across military Services as well as in the Defense Health Agency (DHA). The resources needed to store, annotate, curate, and analyze this type of data is not fully available. To tackle these challenges, we have initiated a quarterly Data Nexus Symposium. Information Papers from the first two events, and invitations to participate in future events, are available upon request. Please send your inquiry to: lori.a.debernardis.ctr@health.mil and anna.k.applegate.ctr@health.mil).
Sprint 2:
This first phase of our approach is nearly complete. Over the past six months we have: Internally reorganized our teams to most efficiently accomplish work; Internally developed a sensor suite and are finalizing a data-aggregation solution (Figure 4) that can be worn by a medic during TC3; Nearly completed an external competition to select a partner sensor suite team that will similarly deliver a medic worn sensor suite and data-aggregation solution; Nearly completed a contract with an industry partner to collect data about combat casualty care from hyper-realistic training environments; Established contracts with partners to help coordinate data standards and interoperability amongst all components and to manage a “data commons” – a data infrastructure available to TATRC and partners for data storage, analysis and model/AI development; Collected over 65 GB of data from 35 high fidelity medical simulation scenarios and dozens of task trainers representing over 250 TC3 tasks and covering information from nearly 50% of the TC3 documentation card (DD Form 1380); Obtained approval for core research protocols involving human subjects; Prototyped data synchronization and annotation software; and, Conducted two Data Nexus Symposiums to gather perspectives, partners, and momentum in scaling data collection efforts.
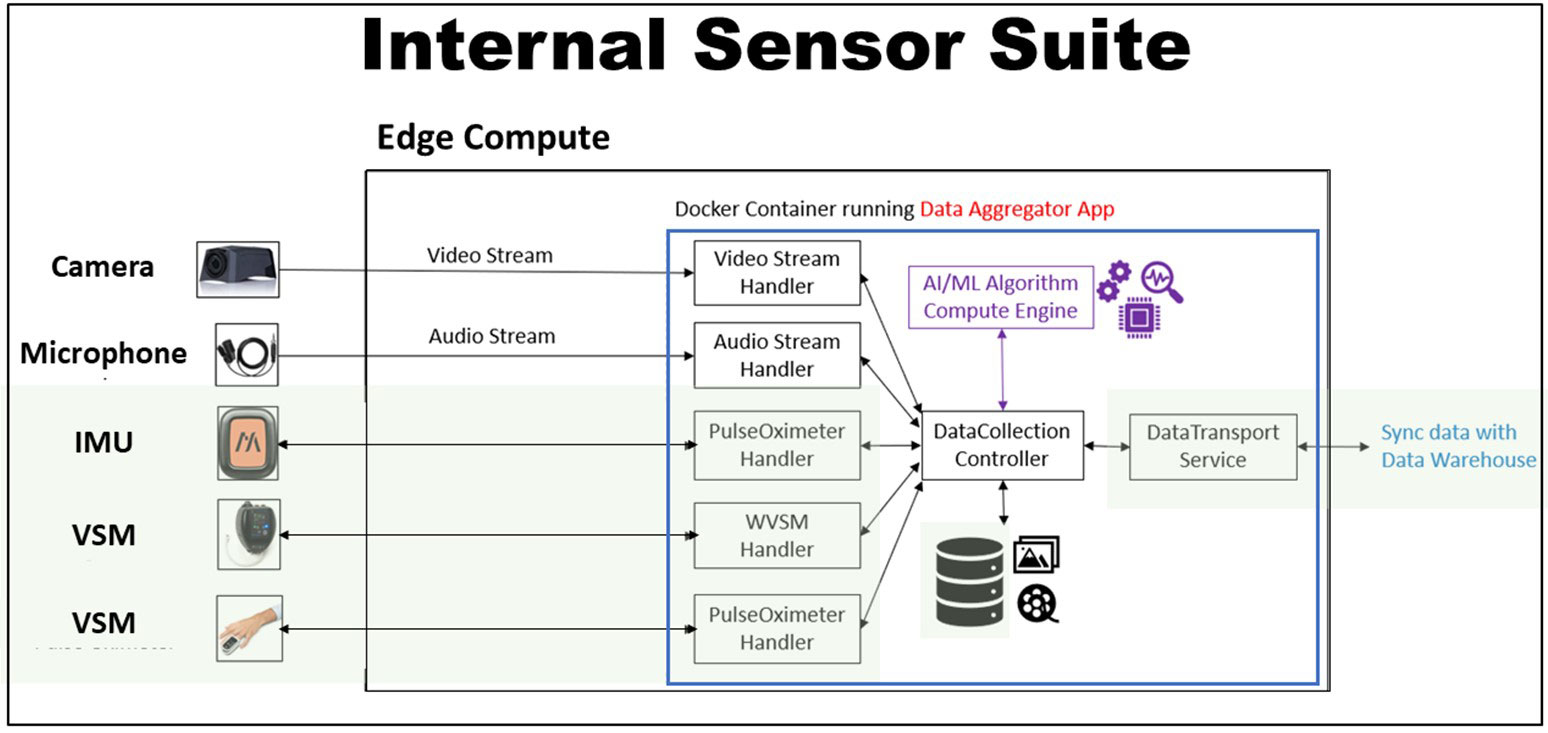 Figure 4. The intramural sensor suite consists of sensors and the “Point of Treatment Aggregation” (POTAG) Software. This software is composed of data handlers for sensor input (Audio, Video, inertial measurement unit and vital signs monitors), a controller interface with compute engine (algorithm), a controller interface with local files storage, and a database interface. Acronyms: inertial measurement unit (IMU); vital signs monitor (VSM); wearable vital signs monitor (WVSM); artificial intelligence (AI); and machine learning (ML).
Figure 4. The intramural sensor suite consists of sensors and the “Point of Treatment Aggregation” (POTAG) Software. This software is composed of data handlers for sensor input (Audio, Video, inertial measurement unit and vital signs monitors), a controller interface with compute engine (algorithm), a controller interface with local files storage, and a database interface. Acronyms: inertial measurement unit (IMU); vital signs monitor (VSM); wearable vital signs monitor (WVSM); artificial intelligence (AI); and machine learning (ML).We are now at the cusp of scaling our data collection within TATRC’s research lab and at partner sites. Over the next six months, we will obtain research and organizational approvals for data collection at our partner sites; ship sensor suites for their use; and collect, annotate, and store data. Simultaneously, we will work with the Medical Technology Enterprise Consortium (MTEC) to identify external algorithm teams through a competitive contracting process allowing us to share data with the selected teams for algorithm development. And, in parallel to the data collection and algorithm development efforts, we will work closely with DoD stakeholders and leverage FFRDC partners at MITRE and MIT Lincoln Labs to evolve data standards, interoperability framework, and data management infrastructure necessary to be successful across the Data Nexus.
Other Important Items to Note:
While I have spent considerable time and effort conveying the importance of the AutoDoc Project, AutoDoc is not TATRC’s only project and it is only the beginning of our Automating Casualty Care Portfolio. In our August 2023 TATRC Times, we introduced the concept of the Automation Stack. AutoDoc is the foundation of the “sense and understand” components of the stack: through passive data collection and modeling of data to produce discrete data necessary to document, AutoDoc makes important information available for other projects. Clinical decision support is essential to maximize capability at the point of need and capacity across the care continuum. With our partners at the Institute of Surgical Research, we continue to revise the Medic Clinical Decision Support System (Medic CDSS) to take advantage of a future where data is made available to it passively and in real-time. We anticipate that an early by-product of the AutoDoc effort will be a Medic CDSS that functions to passively monitor medic actions during TC3 to ensure that necessary interventions are not missed and a version that functions actively to coach a non-medical provider through the steps of TC3; similar to how an automated external defibrillator prompts a lay person to save the life of someone in cardiac arrest.
In parallel to our passive data collection and algorithm development efforts at the “bedside,” we continue to evolve sensing capabilities “at a distance” in collaboration with the Defense Advanced Projects Agency (DARPA) Triage Challenge (DTC) and our Vision and Intelligence Systems for Medical Teaming Applications (VISTA) Project. This project has generated significant interest at multiple exercises for its ability to identify potential casualties at a distance and to determine their general condition by monitoring vital signs remotely. We anticipate that this technology – incorporated into drones, robotic agents, fixed cameras, etc. – will help to prioritize medical responses to mass casualty events and to help monitor casualties waiting for medical care to arrive. There are multiple efforts in the DoD – like DTC - seeking to automate “sensing” across the care continuum. This demonstrates the foundational importance of our work both to amass data about care to build AI models and to leverage the data from sensors to enable future medical concepts. Through collaboration and sharing best practices, we hope to help field trusted solutions faster.
Similarly, the Remote Patient Management System (RPMS), a software solution that we developed during COVID under FDA Emergency Use Authorization (EUA) that enables remote control of multiple commercial life-support medical devices like mechanical ventilators, monitors, and IV pump, represents another foundational component of an ecosystem that can help manage large numbers of casualties with fewer trained humans. In the future, many of the functions of the RPMS device will likely be automated (e.g., autonomous mechanical ventilation, autonomous resuscitation with IV fluids/medications), but, at least in the foreseeable future, these autonomous algorithms will reach limits of execution. In these situations, where the context of care dictates there are few or no trained providers, but a trained medical provider is needed to help the machine decide, that remote control of the medical devices will be necessary. Consequently, reach-back to a remote expert using telemedicine, at least for a long while, will always be a necessary component of any autonomous medical system – we are, and will remain, the Telemedicine AND Advanced Technology Research Center.
As TATRC’s portfolio of work continues to evolve we anticipate a convergence of technologies like AutoDoc, Medic CDSS, VISTA, and RPMS into an ecosystem of solutions to help manage single casualties for inexperienced or untrained caregivers, or massive casualty volumes within the care continuum using fewer human agents. The data collected, analyzed, and modeled at the right location within the echelons of care, will help to optimize the efficiency of the system to deliver the right care with the right resources to the greatest number of casualties. This will offer battlefield commanders a great deal of agility in responding to dynamic battlefield conditions – optimally managing casualties within the fight and maximally returning the ill or injured to duty, rapidly evacuating casualties when possible and necessary, and ideally matching resources to casualty needs (i.e., triage). This will be the key challenge for TATRC and its’ partners over the next decade: bringing together the essential, real-time, reliably collected, and meaningful data across the care continuum in such a way that we can optimize the entire system of care… and that’s a topic for the next edition.
Conclusion:
As I opened this narrative, I will close it by praising the people who work at TATRC; our family of renegades, innovators, disruptors, and visionaries; the hard working-behind-the-scenes team that ensures progress at every step; our partners, friends, and supporters who show up, provide critical perspective, and knock-down barriers on our behalf. THANK YOU ALL for what you do. For continuing to fight for delivery of better solutions that increase our collective capability and capacity to heal and protect our Nation’s most valuable asset: our Service Members.
References:
Birch E, Couperus K, Gorbatkin C, Kirkpatrick AW, Wachs J, Candelore R, Jiang N, Tran O, Beck J, Couperus C, McKee J, Curlett T, DeVane D, Colombo C. Trauma THOMPSON: Clinical Decision Support for the Frontline Medic. Mil Med. 2023 Nov 8;188(Suppl 6):208-214. doi: 10.1093/milmed/usad087. PMID: 37948255.
For more information on this initiative, contact Mr. Nate Fisher at nathan.t.fisher3.civ@health.mil.
This article was published in the April 2024 issue of the TATRC Times.